The parts of the agent stack and what they do

Developer Relations

To build a production-ready agent, you need more than a powerful model. You need a stack. In this article, we'll attempt to navigate the rapidly evolving terminology in the agent landscape. We'll look at three layers of the AI stack that have been emerging over the past few months: framework, runtime, and harness.
If you've read articles about building AI agents and come away more confused about the difference between the various terms, you're not alone. We'll start with the simplest unit and layer in solutions to the problems that emerge as an agent moves from demo to production.
What is an agent?
Even the the exact definition of an agent is still contested, but a useful place to start is that an agent is an LLM in a feedback cycle with tools, acting toward a goal. The model generates tokens. The tools allow it to interact with the world. The loop allows it to observe the result of those actions and reason about the next step.
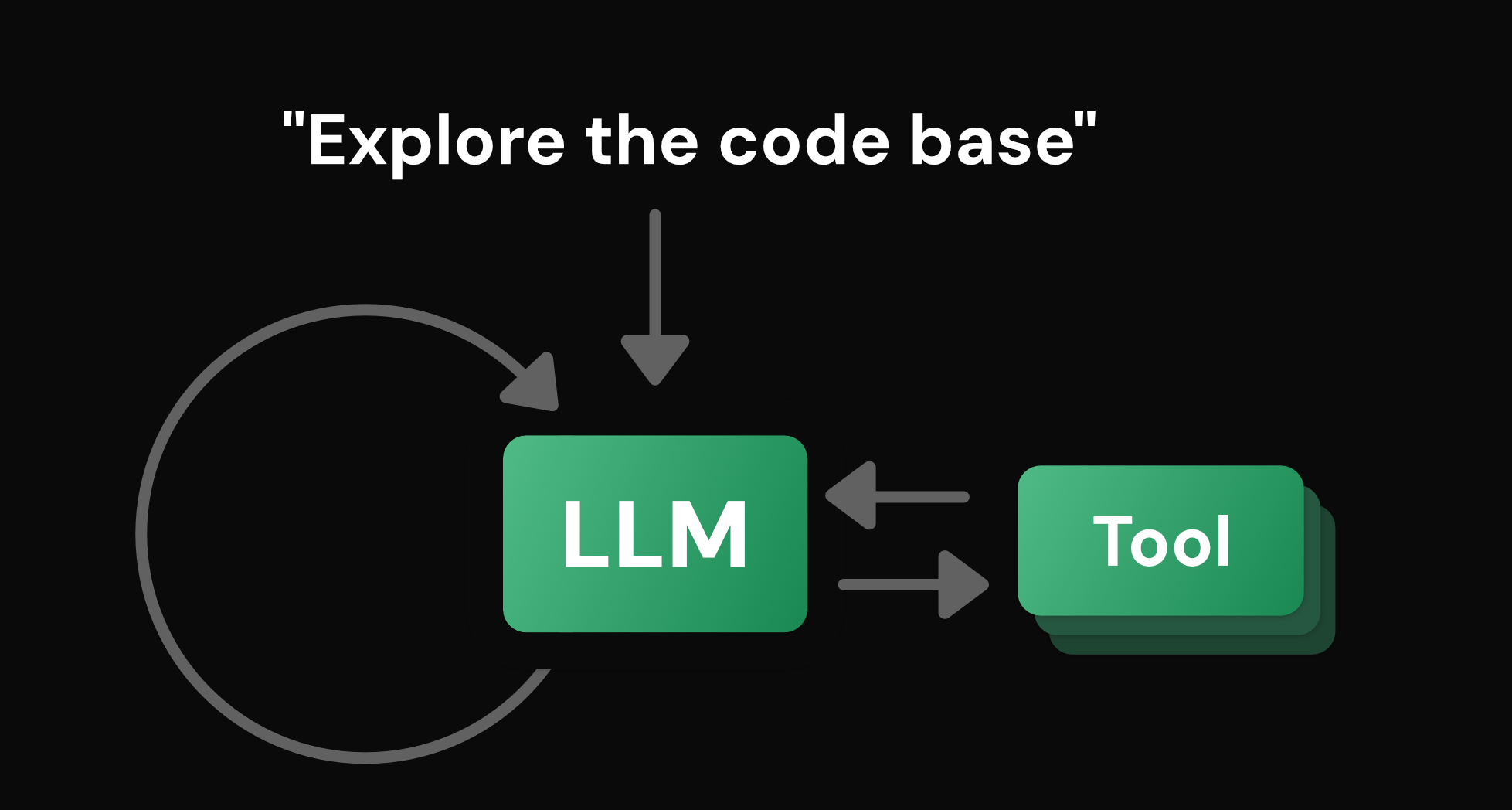
But that definition leaves out much of what makes an agent so powerful. It's everything built around that loop that separates a pretty demo from one that can run in production.
If you implement this as a simple script, it works for about thirty seconds. Then the context window fills and the agent forgets what it was doing. The process crashes and the agent is gone. It makes a mistake and no one can intervene. You have something that you can show your friend, but collapses the moment it meets reality.
The framework: one loop, any model
The first problem is inconsistency. If you write your own loop and tool-calling logic, your agent is tightly coupled to a specific model's API. If you want to swap models or add new tools, you're rewriting your core logic.
Instead of building the logic from scratch, consider using a framework.
A framework is a library of abstractions and integrations. LangChain, Vercel AI SDK, OpenAI Agents SDK, CrewAI, Google ADK, and LlamaIndex are all frameworks. They give you consistent tool interfaces, stable message formats, and the loop itself abstracted away from the model call.
The framework makes the agent composable. You can swap models without rewriting your tool layer. But while the agent is now organised, it still can't survive a crash.
The runtime: survive the restart
The second problem is durability. Production agents often run for minutes or hours. They need to handle retries, state persistence, and concurrency. Without a runtime, the agent is gone the moment the server restarts mid-task.
A runtime adds durable execution (surviving crashes and restarts), state persistence (saving where the agent left off), streaming, and human-in-the-loop interrupts. Temporal, Inngest, and LangGraph are examples of runtimes.
The runtime ensures that the agent can run for hours, survive infrastructure failures, and hand control back to a person when it's uncertain. Now the agent is stable, but it still can't think beyond the next immediate step.
The harness: think beyond the next step
The final problem is complexity. Even a stable, standardised agent can collapse on a multi-step, non-deterministic task. It loses track of the goal or gets stuck in a loop.
This is where the harness comes in.
The harness is the top layer of the stack. It orchestrates the agent's cognitive resources.
The harness provides:
- Advanced planning: Task decomposition and todo tracking.
- Context management: Summarisation, eviction, and keeping the window focused on what matters.
- Specialised tooling: Predefined primitives for filesystem operations, bash execution, and search.
- Delegation: Creating subagents with clean context boundaries to handle specialised sub-tasks.
Let's consider a coding agent. The framework gives it a model-agnostic loop. The runtime lets it survive a thirty-minute refactoring session without losing state. The harness provides tools for file reads and bash execution, and subagents for codebase navigation. These features let it plan a multi-file change and keep its context focused on the task at hand.
OpenCode, Pi, and Claude Code are all examples of agent harnesses.
Same model, different outcomes
Together, these layers form the infrastructure that wraps the model. In a broader sense, everything that isn't the model is the harness; but architecturally, the harness is the layer where the highest leverage lives.
Running the same model in different harnesses may produce vastly different outcomes. At the time of writing, Opus 4.6 in a custom harness (ForgeCode) ranks 4th on Terminal Bench 2.0, while the same model in Claude Code ranks 40th. The model is the same. The harness makes the difference.
In practice, runtime and harness are non-negotiable for a production agent. The framework is optional. Some teams skip it entirely and build directly on a runtime.
It's worth noting that the definition, responsibilities, and boundaries of each layer are still evolving. For example, LangGraph spans framework and runtime, Claude Code bundles a runtime inside the harness, and "harness" itself is still a contested term.
From prompt tuning to harness engineering
The first wave of frontier models gave rise to prompt engineering — teams realised that the prompt itself could drastically shape the output. A second discipline is now emerging around the layers wrapping the model: harness engineering, the iterative shaping of those layers to get better outcomes from the agent.
Harness engineering involves things like progressive disclosure (surfacing knowledge to the agent only when it needs it) and structural constraints (tools and scripts the agent can't violate). Both usually emerge through what Addy Osmani calls the ratchet principle: every recurring mistake becomes a permanent rule baked into the environment, not a line in a prompt.
It's also permanent, ongoing work. Better models don't reduce the harness work; they redirect it. Each new model closes off some patterns and opens up others, so it's worth auditing your harness when a new model lands. Some constraints will be redundant.
A year ago, the headline question was which model? Increasingly, it's what's your stack? The model still matters, but the gap between teams is opening up around it. The harness is where most of the active experimentation is happening.
The interesting decisions aren't about picking a winner at each layer. They're about what to build, what to buy, and what to skip entirely.
What does your stack look like? Join the discussion on the Berget AI Matrix server.